Lise Stork, VUA.

Scientific discovery aims to explain the mechanisms that govern our world. In the social sciences and humanities, scientists are interested in our social world; societies and the individuals within them. They research, for instance, the mechanisms that cause social divides. Why do some groups die younger than others? Why do women earn less than men? How do the occupations of your (grand)parents influence your own career?
In the natural sciences, one talks about ‘theories’, ‘mechanisms’ and ‘laws’, where the emphasis lies on mathematical calculation, precise theories and experimental design of research studies. The same is not as trivial for (historical) social sciences, where researchers rely mainly on observational studies instead of experimental studies, and test research hypotheses in which variables are often social constructs: concepts that do not exist in our objective reality, but through interactions between humans, for example intelligence or nationality.
Both strands of science share that they want to further scientific discovery, and thus find it crucial to be precise and transparent about what is measured and what that means. Transparency is paramount for uptake and reuse of scientific output, which are necessary ingredients in the cycle of scientific discovery (see figure). Existing work lays the foundation for the generation of novel hypotheses. For the social sciences and humanities, where variables can be social constructs, such transparency is crucial as hypotheses might be tested with distinct constructs in the methods section. For example, how was social stratification–the ranking of people according to their occupation-measured? What classification was used to measure social class? What characteristics were measured to create a variable for well-being?
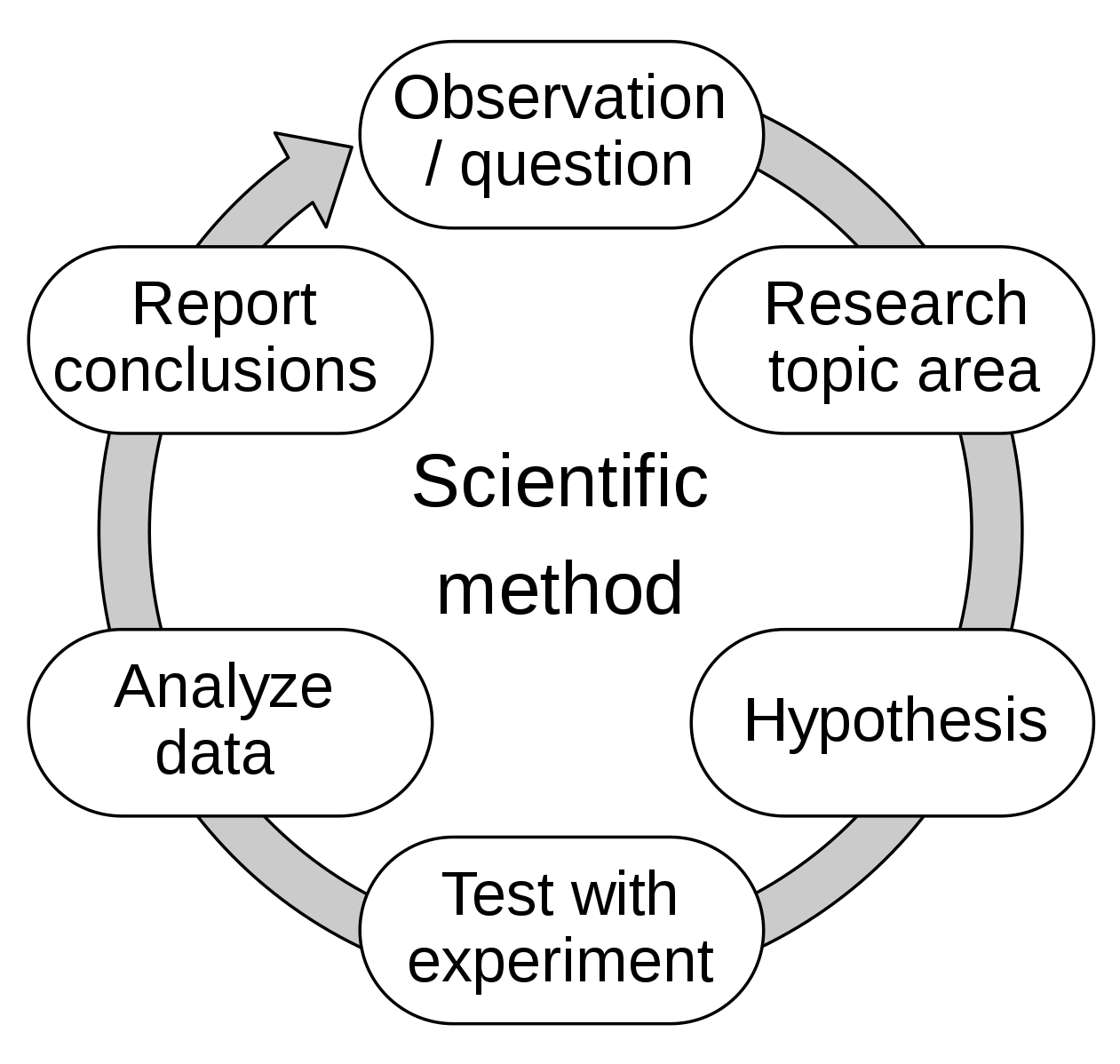
The scientific method. cc Efbrazil, CC BY-SA 4.0
via Wikimedia Commons
The complexity of these social constructs make surveying the literature for hypotheses, results and their specific measurements a cumbersome task. Natural language can be ambiguous or unclear, and therefore challenging to be interpreted precisely by humans as well as machines. After a literature search, specific details on what has been measured and why need to be rediscovered through precise reading, and related to what has been done in other studies. There is thus a need for the improvement of the digital infrastructure underlying scientific publication, to stimulate a deep understanding, and reuse of existing hypotheses, methods and findings.
Researchers in the MUHAI project together with domain experts from the International Institute of Social History (IISG) try to enhance the comparability of research outcomes. Inspired by the Semantic Web community’s agenda to make knowledge and data FAIR: findable, accessible, interoperable and reusable, these researchers aim to publish scientific hypotheses online as structured data. Specifically, work is being done on (i) the development of a semantic model for capturing social history hypotheses, and (ii) a digital assistant for authoring of social hypotheses as structured data, as well as the design of novel experiments. With such an application, we work towards a shared knowledge database, a shared memory of social science and humanities knowledge, that can be used in a variety of applications: from semantic search over the body of literature, to the automated discovery of novel insights and research hypotheses.
Credits
Intro image - Quarto Stato by Giuseppe Pellizza da Volpedo via Wikicommons
{kind=link}

Study without ChatGPT… to work more wisely with AI

From digital archives to online observatories, the peaks and chasms of social-media based research Pt.3

From digital archives to online observatories, the peaks and chasms of social-media based research Pt.2

From digital archives to online observatories, the peaks and chasms of social-media based research Pt.1

Narrativizing Knowledge Graphs

Economists’ inequality narratives (on Twitter) before and after the COVID-19 outbreak

Making sense of events within a story

Talking (online) about inequality: Towards an observatory on inequality narratives
