Remi van Trijp and Martina Galletti, CSL.

One of the reasons why it is so difficult to develop human-centric AI systems is that such systems need to "understand" the world and human activities in a way that is compatible with how humans make sense of the world. The crux of the matter is that each person has their own unique way of doing so: reality is so mind-bogglingly complex that we constantly need to make choices about which information is relevant, and which elements of a situation should be highlighted or obscured. This process – in which a person puts a situation in a particular perspective to express their beliefs, desires, and intentions – is called "framing".
A “frame” is a structured piece of knowledge that we build up and maintain through experience. At its most basic level, a frame can be considered as a template of a scene with several open roles (called “Frame Elements”) that need to be filled in.

Figure 1 illustrates a scene that we may perceive, and everyone who has ever prepared a meal in a kitchen can immediately “frame” the scene. There are multiple frames possible, such as “Cooking”, but here we decided to frame the woman’s activity as a “Baking” event. The Baking frame includes several Frame Elements such as the person who does the baking, the food that is being prepared, utensils for doing so, a time and place (usually the kitchen), and so on. We can then communicate about what is happening depending on which aspects of the frame we wish to emphasize:
- The woman is baking a cake (with the frame elements: baker + baked food
- She is stirring in the pot (with the frame elements: baker + utensils)
- She’s in a kitchen (with the frame elements: baker + location
- …
Frames can also be more complex. For instance, they can propose a particular viewpoint on an event, allowing us to see the same event from different viewpoints. A classic example is the "buyer" versus "seller" frames, in which the same transaction can be viewed from the perspective of the buyer (e.g. "She bought cookies from my niece") or the seller (e.g. "My niece sold her some cookies"). Frames can also “evoke” a wide range of associations. For instance, sentences such as "COVID-19 is an invisible enemy" evokes frames about fights and wartime, and invites the addressee to make sense of the COVID-19 pandemic in such terms. The way a society perceives a particular issue may have important effects on policy making: if COVID-19 is seen as an enemy of the people, citizens will perhaps demand more far-reaching action from their governments. If however COVID-19 is seen as “a hoax”, people might resist any new policy decision.
In other words, if we want artificial systems to understand how humans perceive and make sense of complex issues, we need to identify how they “frame” particular events. Since language is one way to peek into the human mind, we can use people’s linguistic behaviors as evidence for how they frame reality. We are therefore working on a “Frame Extractor” that aims at identifying which frames people express in natural language texts written in Dutch, English, French, German, Italian and Spanish. Since these European languages are sufficiently similar to each other, we are working on a single repository of frames that can be shared by each language model.
One example is the Causation-frame, which (as you can guess from its name) frames an event in terms of a Cause-and-Effect relation. For example, in the sentence “Respondents believe that the coronavirus will cause an increase in income inequality in their country”, the Causation frame imposes a causal relation between “the coronavirus” (cause) and “an increase in income inequality in their country” (effect). The same sentence also expresses other frames: the Belief-frame (with “respondents” as the Believer, and the whole subclause as the Belief), and Future-frame (with the auxiliary will marking that the Causation-frame is a future possibility).
So how does our Frame Extractor work? A typical workflow starts by preprocessing and preparing a document using neurostatistical language processing tools (such as SpaCy), which includes tasks such as part-of-speech tagging (e.g. recognizing whether a word is a noun or a verb), tokenization (dividing a document into sentences, and sentences into words), and dependency parsing (identifying syntactic relations between words). Using another software library we developed in the MUHAI project, the result of preprocessing is then automatically translated into a symbolic representation that is readable both by human experts as by our computational platform called Fluid Construction Grammar (FCG), which is an open source special-purpose programming language for implementing grammars based on the notion of a “construction”. A construction can be thought of as a mapping between a form or a (syntactic) pattern on the one hand, and a meaning on the other. These constructions are used for identifying which parts of a sentence can be associated to the frames in our shared repository, and which frame elements are expressed in the sentence.
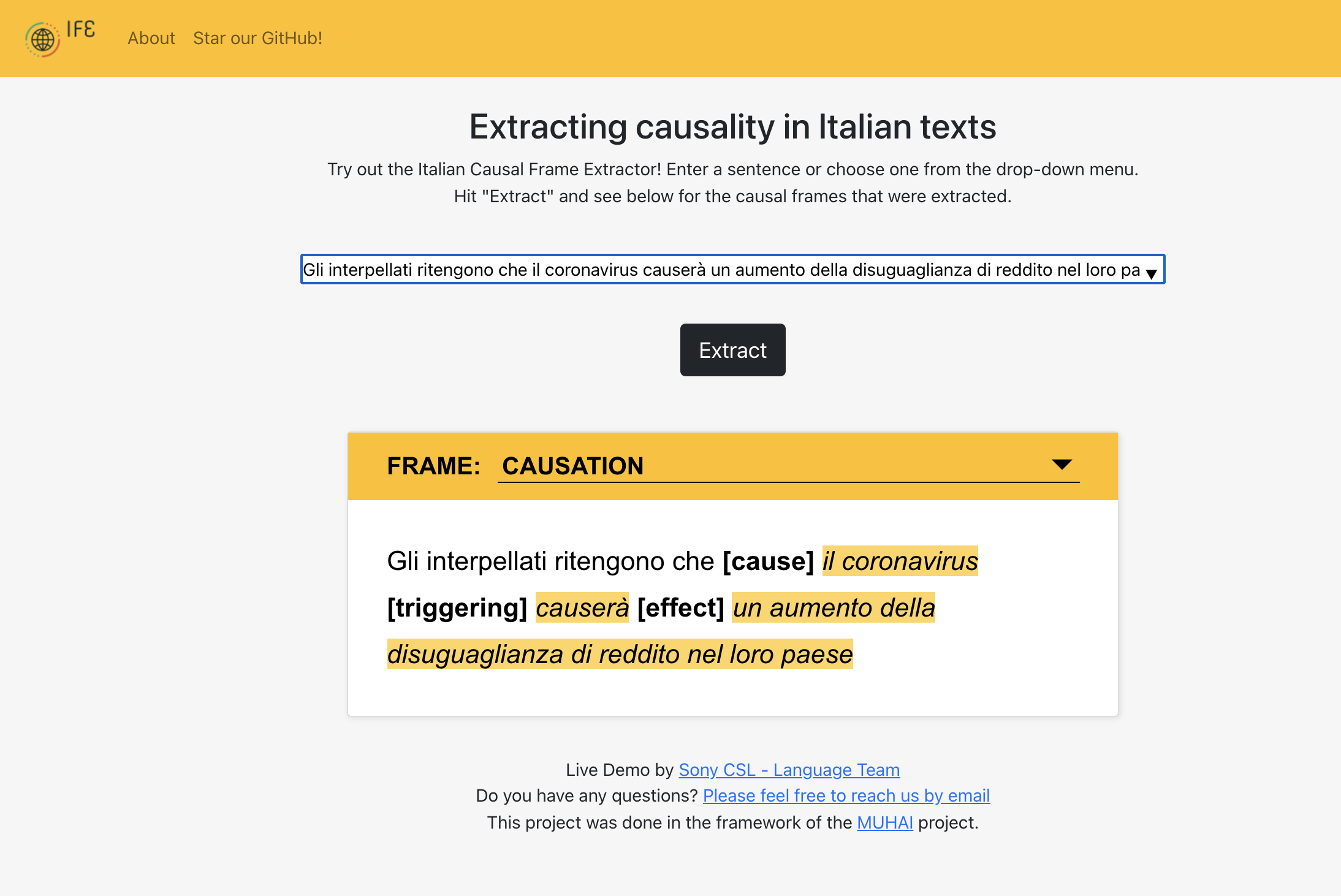
As an illustration, let us translate the aforementioned coronavirus example in Italian, and see how the Italian Frame Extractor is able to identify the Causation frame:
“Gli interpellati ritengono che il coronavirus causerà un aumento della disuguaglianza di reddito nel loro paese.”
Frames are typically identified by lexical or idiomatic constructions, which map a word or phrase onto a frame definition. In this example, we have a very clear lexical unit that triggers the Causation-frame: “causerà” (“will cause”). This construction will then introduce the Causation-frame, but now we still need to identify which Frame Elements are expressed. This task is performed by grammatical constructions: since the verb occurs in the Active Voice, we can infer from its lexical definition that its subject (“il coronavirus”) is the Cause, and that its Direct Object (“un aumento della disuguaglianza di reddito nel loro paese”) is the Effect. As can be seen in Figure 2, the Italian Frame Extractor indeed successfully identifies the Causation-frame and these two Frame Elements, and highlights the corresponding phrases in the text.
Depending on the kind of human-centric AI system that we want to develop, there are two ways of extracting frames that we call “phrase-based” and “meaning-based”. A phrase-based frame extractor can be seen as some kind of text annotator: given a document, it needs to identify which parts of the text may evoke a frame (“Frame-Evoking Elements” or FEEs), and then annotate which phrases are assigned to which frame elements, as we showed in Figure 2. While such a Frame Extractor is relatively shallow in the sense that it does not try to comprehend a text, it is already very useful for important applications, such as extractive search (e.g. for journalists or policy makers who need to browse through large amounts of documents). Meaning-based frame extraction, on the other hand, is not about annotating a text but translating it into semantic representations that are useful for other tasks that require comprehension. Again, many applications can be envisaged for this type of frame extractor: it can be used for automatically populating ontologies and event-based knowledge graphs based on textual data, for improving difficult tasks that require more semantic information such as Entity Linking and Reference Tracking, and so on.
Since the MUHAI project is all about human-centric AI, we will make our Frame Extractors publicly available to the research community as an open source software library, with a first release for English and Italian in March 2022; followed by a yearly update and release for French (2023) and for Spanish and German (2024).
Credits
Intro photo by Visual Stories || Micheile on Unsplash
Photo of Figure 1 by Jason Briscoe on Unsplash

Uncommon Ground

Do you speak AI?

Pragmatics: the secret ingredient

Deconstructing Recipes

Foundations for Meaning and Understanding in Human-centric AI

The FCG Editor: a new milestone for linguistics and human-centric AI

Linguistic Alignment for Chatbots

MUHAI Visual Identity
